

 入田
入田
AIを無料で学べるKIKAGAKUを開発した入田@guru_takaです。
今日まで約1ヶ月間、機械学習(ディープラーニング含む)を学習。
習作として初めてのAIアプリ『Perfume AI画像診断』を開発したので、使用技術を書きました!
こちらのリンクからPerfumeの画像をアップロードすると、メンバーをAIが識別してくれます!
→ Perfume AI画像診断
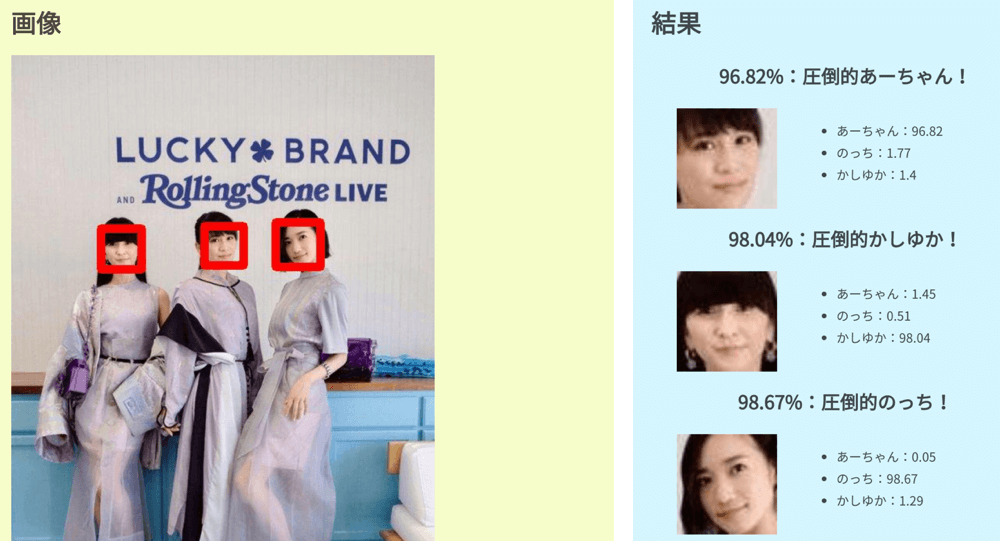
Perfume以外の画像をアップロードすると、似ていなかったとしても、特徴が最も似ているメンバーの確率を出力。カオスな結果も出ますが、気にしないで下さい。笑

この記事では、『Perfume AI画像診断』の技術的な話をしていきます。AIアプリ開発をしてみたい方、気になっている方は必見です!
アーキテクチャ
アーキテクチャは下図になります。
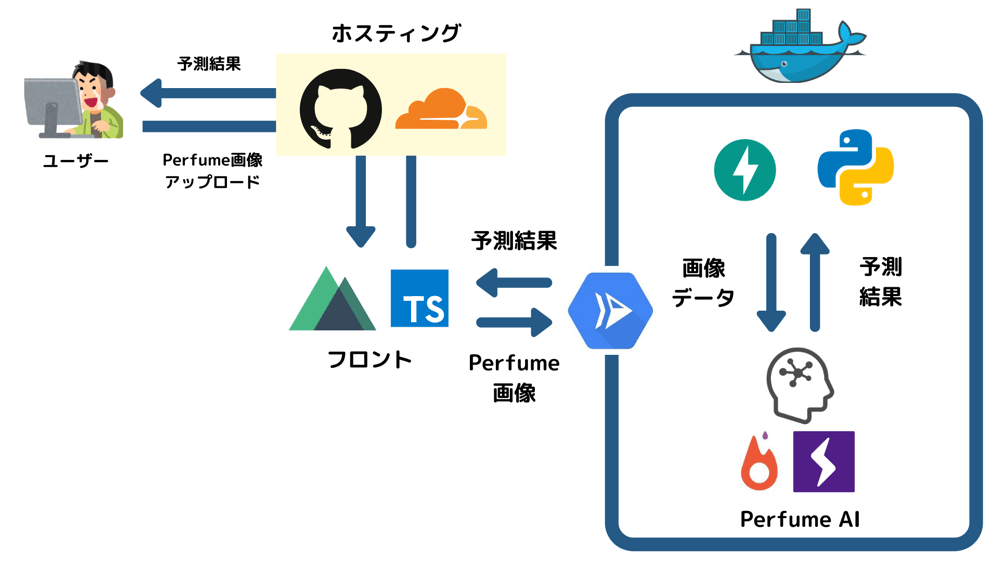
- フロントエンド:Nuxt(Typescript)
- 学習済みモデル:PyTorch・PyTorch Lightning(Python)
- APIサーバー:Cloud Run・FastAPI(Python)
- ホスティング:GitHub Pages
- CDN:Cloudflare
APIサーバーはGCPの1つで、コンテナをサーバーレスに実行できる『Cloud Run』にデプロイしています。
またPerfumeの画像診断の頭脳(AI)はPyTorch、ラッパーにPyTorch Lightningを使いました。
フロントエンドはNuxtを使い、初めてのTypeScriptを導入しています。
開発フロー
ザックリとした開発フローはこんな感じです。
各ステップごとにコードや詰まった点を紹介していきます。
STEP.1:Perfumeの画像データ集め

まずはPerfumeメンバーの画像を集めました。方法は主に3つです。
- Goolgeから画像スクレイピング
- インスタ
Google Images Downloadを使って、Goolgeから画像スクレイピングしました。
参考
Joeclinton1/google-images-download at patch-1Github
以下のコマンドだけで簡単にできます。
$ git clone https://github.com/Joeclinton1/google-images-download.git
$ python3 google-images-download/google_images_download/google_images_download.py -k 取得したいキーワード
最初は「Perfume あーちゃん」というキーワードのほかに、「壁紙」というキーワードも入れたりすると、良質な画像がたくさんゲットできてオススメです!
Google画像スクレイピングだけでしたが、STEP3のAI開発で良い制度が出なかったので、インスタでの画像集めもスタート。スクレイピングも検討しましたが、勢いで自力でスクショしています。
Perfumeだから良かったものの、おじさんとかの画像を集めてたら、病んでましたね。
STEP.2:顔の切り抜き+ラベリング(前処理)
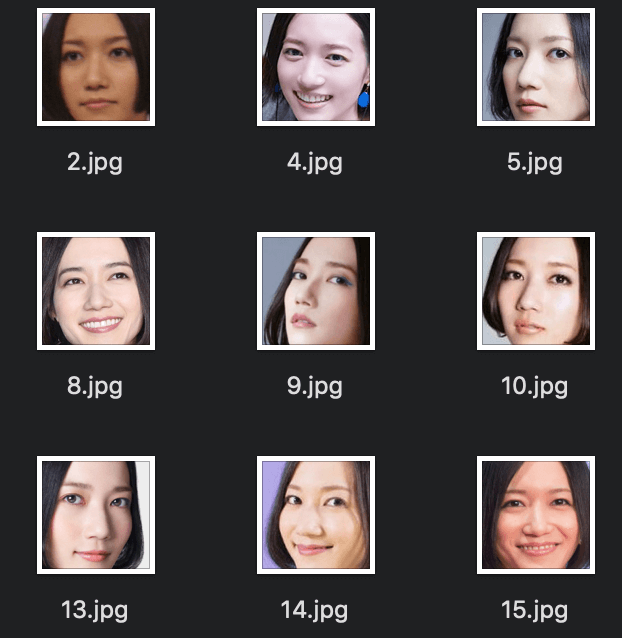
次に、集めた画像から顔だけ切り抜く作業をします。実行環境はJupyter Notebookです。opencvで、画像から顔を抽出し、切り抜いて保存しています。
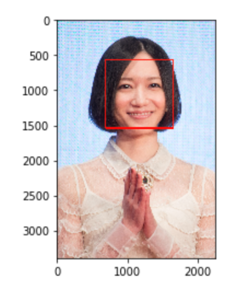
ソースは私のリポジトリにありますので、気になる方は参考にしてみて下さい!
参考 gurutaka/cut_face_imgs_scriptGithub
以下の記事を参考にしています。
参考 ディープラーニングでザッカーバーグの顔を識別するAIを作る①(学習データ準備編)Qiita
のっち、あーちゃん、かしゆか画像をラベリングする作業は手動です。またノイズになる画像(Perfume以外の顔)も自分で除きました。
最終的に、各メンバーそれぞれ164枚の良質な顔画像をゲット!
STEP.3:学習済みモデルの開発
次にAIアプリを開発していきます。開発環境は無料でGPUを使うために、Google 今回はディープラーニングで多く用いられるファインチューニングを使いました。
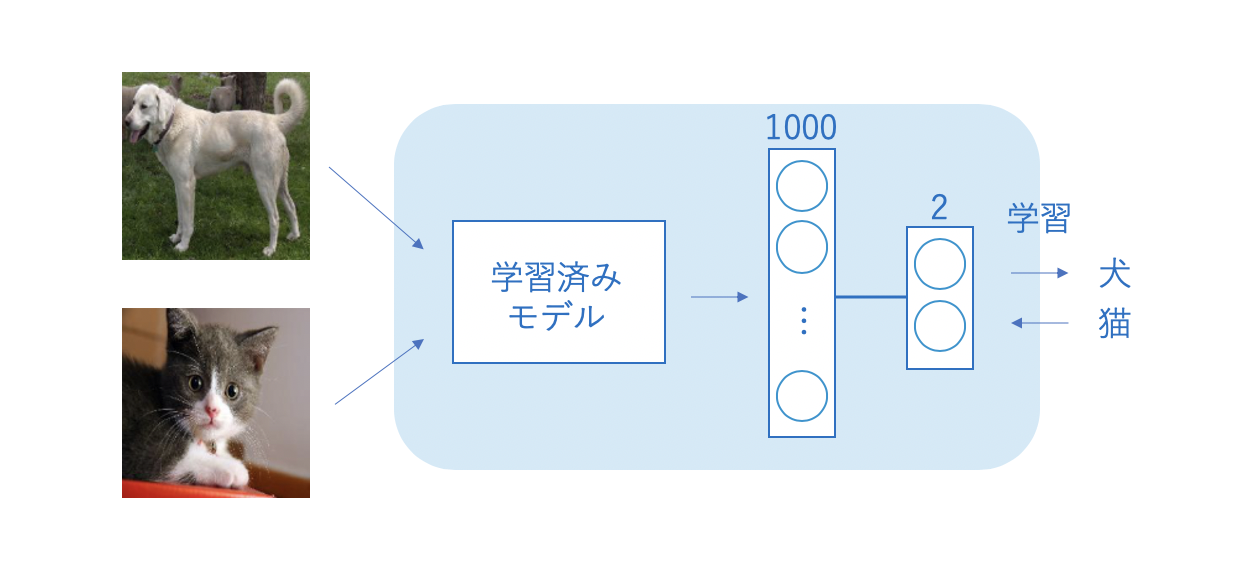
ファインチューニングの説明をKIKAGAKUから引用します。
ファインチューニングとは、異なるデータセットで学習済みのモデルに関して一部を再利用して、新しいモデルを構築する手法です。モデルの構造とパラメータを活用し、特徴抽出器としての機能を果たします。
手持ちのデータセットのサンプル数が少ないがために精度があまり出ない場合でも、ファインチューニングを使用すれば、性能が向上する場合があります。
ファインチューニング – KIKAGAKU
実はCNNの畳み込み部分(特徴抽出器)も実装しましたが、ファインチューニングの方が圧倒的に精度が良かったです。検証用データの精度の比較はこちら!
- 自作CNN:78%
- ファインチューニング:96%

ファインチューニングの凄さに度肝を抜かれました。圧倒的です。データ数が少ない場合は、とりあえずファインチューニングを試したほうが良いですね。
コードですが、KIKAGAKUの掲載コードと似ています。解説もありますので、気になる方はぜひチェックしてみて下さい!
参考
ファインチューニング(PyTorch)KIKAGAKU
私の学習済みモデル作成のコードも置いておきます。
参考
perfume-ai/main.ipynb at master · gurutaka/perfume-aigithub
STEP.4:APIサーバー構築
次は、ユーザーが画像をアップロードした際、学習済みモデルで予測し、結果をフロントに返すAPIサーバーを開発します。APIフレームワーク「FastAPI」を使い、Cloud Runにデプロイしました。
Dockerfileは以下の通りです。
FROM python:3.6
# FastAPI
RUN pip install fastapi uvicorn
# PyTorch関連
RUN pip install torch torchvision pytorch-lightning
RUN pip install numpy
# opencv
RUN apt-get update -y && apt-get install -y libopencv-dev \
&& apt-get clean \
&& rm -rf /var/lib/apt/lists/*
RUN pip install opencv-python
COPY . .
# 起動
CMD uvicorn main:app --host 0.0.0.0 --port ${PORT}
初めてFastAPIを使いましたが、書き方がシンプルで個人的に凄い良かったです!公式ドキュメントも丁寧かつ、サンプルコードも豊富で助かりました。
参考
FastAPI公式ドキュメント
実装する際にCROS問題とPOSTで役立った公式の記事を載せておきます。
参考
CORS (Cross-Origin Resource Sharing)FastAPI
参考
Request BodyFastAPI
画像データと推論結果の内部処理ですが、ザックリまとめると
- base64でエンコードされたの画像データをAPIサーバーにPOST
- 受け取った画像データをデコード
- 学習済みモデルで推論
- 推論結果と、切り取った顔画像をbase64形式にエンコードし、レスポンス
しています。
Base64を使っているので、画像をDBに保存することもしていません。pythonでのbase64のエンコード・デコードは以下の記事が参考になりました。
参考
【Python】Base64でエンコードされた画像データをデコードする。Qiita
以下リンクが、実装したAPIサーバーの最終コードのリポジトリになります。
参考
perfume-ai/api at master · gurutaka/perfume-aiGithub
APIサーバー構築のラスト、Cloud Runにデプロイした際、こんなエラーが起きました。

FastAPIのHello Worldは問題なくデプロイできたので、PORTの設定が原因ではないと思い、ログをチェック。
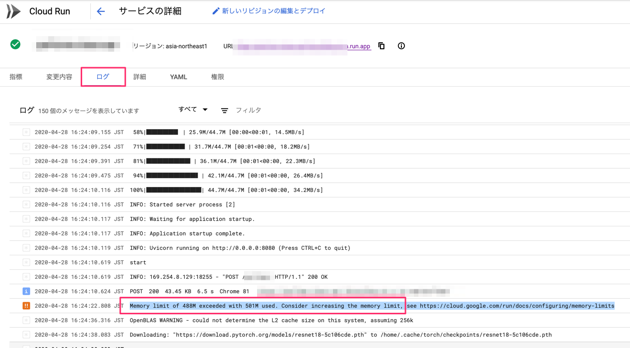
すると、メモリオーバーしているとのこと。以下の手順で、メモリ上限を上げて無事にデプロイできました!
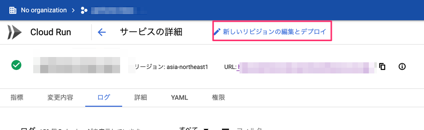
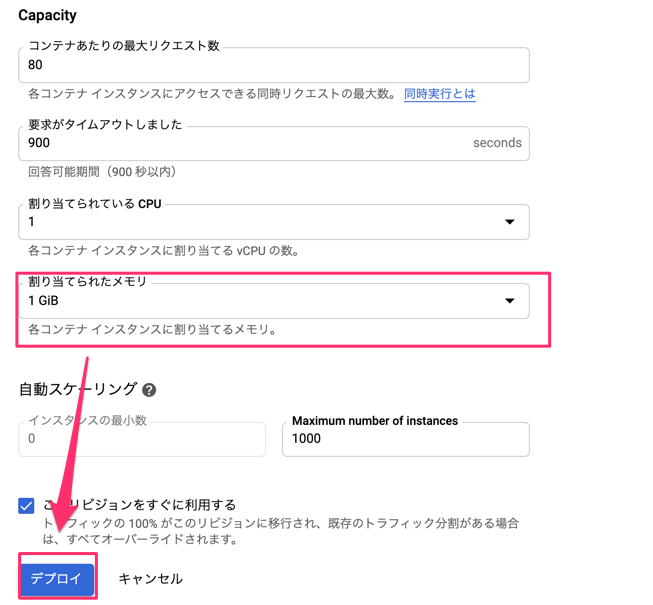
STEP.5:フロント開発
フロントの開発はいつも通りの開発していたのですが、1つだけ工夫したことがあります。base64でエンコードする際に、ブラウザ側でリサイズしています。
というのも、スマホでビックサイズな画像をアップロードされると、cloud runがメモリオーバーして、動かなくなってしまうんです。なので、クライアント側でリサイズ処理をしました。
実装方法ですが、compressorjsライブラリを使っています。canvasも使わず、簡単にリサイズできてめっちゃ便利!!!
参考
fengyuanchen/compressorjs: JavaScript image compressor.github
こちらの解説記事がとてもわかりやすいので、気になる方はぜひチェックしてみて下さい!
参考
画像をアップロード前に圧縮する流行りの方法【Vue.js x Firebase x 令和】Qiita
最後に
以上になります。初めてAIアプリを開発しましたが、データ集め&前処理がここまで大変だとは思いもしなかったです。また1つ良い経験ができました!
また、1ヶ月でまさか自分がAIアプリを開発できるようになんて…と嬉しい思いで一杯です。
弊社が無料で公開しているKIKAGAKUには、サンプルコードあり、またわかりやすい図でAIのいろは、また実装方法が学べます。私自身、KIKAGAKUでも学びました。
AIを作れるようになりたい!という方は、ぜひKIKAGAKUで学んでみて下さい。心の底からオススメできます!






まずは無料で学びたい方・最速で学びたい方へ
まずは無料で学びたい方: Python&機械学習入門コースがおすすめ

AI・機械学習を学び始めるならまずはここから!経産省の Web サイトでも紹介されているわかりやすいと評判の Python&機械学習入門コースが無料で受けられます!
さらにステップアップした脱ブラックボックスコースや、IT パスポートをはじめとした資格取得を目指すコースもなんと無料です!
最速で学びたい方:キカガクの長期コースがおすすめ

続々と転職・キャリアアップに成功中!受講生ファーストのサポートが人気のポイントです!
AI・機械学習・データサイエンスといえばキカガク!
非常に需要が高まっている最先端スキルを「今のうちに」習得しませんか?
無料説明会を週 2 開催しています。毎月受講生の定員がございますので確認はお早めに!
- 国も企業も育成に力を入れている先端 IT 人材とは
- キカガクの研修実績
- 長期コースでの学び方、できるようになること
- 料金・給付金について
- 質疑応答
